

Notes from the new OCP FTI workstream, the first 19 community survey responses, a deep dive on hardware management, and what FarmGPU is contributing in 2026.
The Open Compute Project (OCP) was founded on a simple idea: when hyperscalers share their designs, the rest of the industry stops re-inventing the same rack, server, and switch over and over. That worked. The problem in 2026 is that "the rest of the industry" now includes a new tier of operators — the neoclouds — who are deploying AI clusters that look hyperscale on the inside but live on neocloud-sized teams, balance sheets, and timelines on the outside.
That's the gap the new OCP Future Technologies Initiative (FTI) workstream, Scaling AI Clusters at Neoclouds, exists to close. I'm chairing the workstream together with co-leads Yann-Guirec Manac'h (Scaleway) and Kyle McCrindle (Denvr Dataworks), and FarmGPU is one of the operators contributing real designs, real survey data, and real production experience back into the open community.
Part 1 — What the workgroup is trying to do
The workstream was officially launched at OCP Global Summit 2025 and is part of the FTI portfolio (alongside Open Systems for AI and Open Cluster Designs for AI). It's an open forum — neoclouds, OEMs, networking and power vendors, colos, and end users — focused on the unique challenges of scaling xPU IaaS/PaaS infrastructure from a single pod to multi-site, hyperscaler-adjacent capacity.
The four goals
- Foster knowledge sharing and best practices. A requested forum for operators to discuss OCP adoption, contribution patterns, and cross-project coordination — both online and at Summits.
- Promote interoperability across scales. Drive integration between small edge AI deployments and large centralized clouds so hybrid neocloud models actually work for training and inference workloads.
- Enhance energy efficiency and share sourcing strategies. Optimize power, cooling, and resource utilization, and share what's working globally for sourcing energy and facilities — first-party and colo.
- Develop open standards for AI infrastructure modularity. Identify the gaps where neocloud-specific patterns aren't yet captured by Open Systems for AI or Open Cluster Designs for AI, and feed those gaps back into the right OCP projects.
Getting facilities — most traditional DCs and colos weren't built for 30–100kW racks, liquid cooling distribution, or AI-grade power topologies.
Getting electrons — grid availability, co-generation, medium-voltage AC vs. high-voltage DC distribution; the data center boundary is moving upstream.
Getting hardware (fast enough) — accelerator allocations, generational upgrade timing, and the management/automation surface area required to actually operate it.
Getting customers — visibility, trust signals, and channels (OCP Marketplace, Experience Centers, Summit panels) that help operators be discovered.
The workstream doesn't traditionally produce specifications itself — that's what OCP Projects do — but it's where neocloud-specific requirements get organized and routed into the right project, particularly Open Systems for AI and Open Cluster Designs for AI.
Part 2 — What the community is telling us
The 2026 Focus Survey
We ran a community survey to set 2026 priorities and got 19 responses from a broadly representative cross-section: nine neocloud operators (Crusoe, Lambda, Scaleway, Denvr Dataworks, LightningAI/Voltage Park, FarmGPU, Edinburgh IDF, and others), three networking vendors, plus power and facilities vendors (Vertiv, Hitachi Energy, AirTrunk), OEMs, OOB management vendors, and consultants.
Twelve of nineteen are already using OCP hardware or designs in some form ("Yes" or "Some"), and eight of nineteen describe themselves as actively scaling across multiple sites or in rapid expansion.
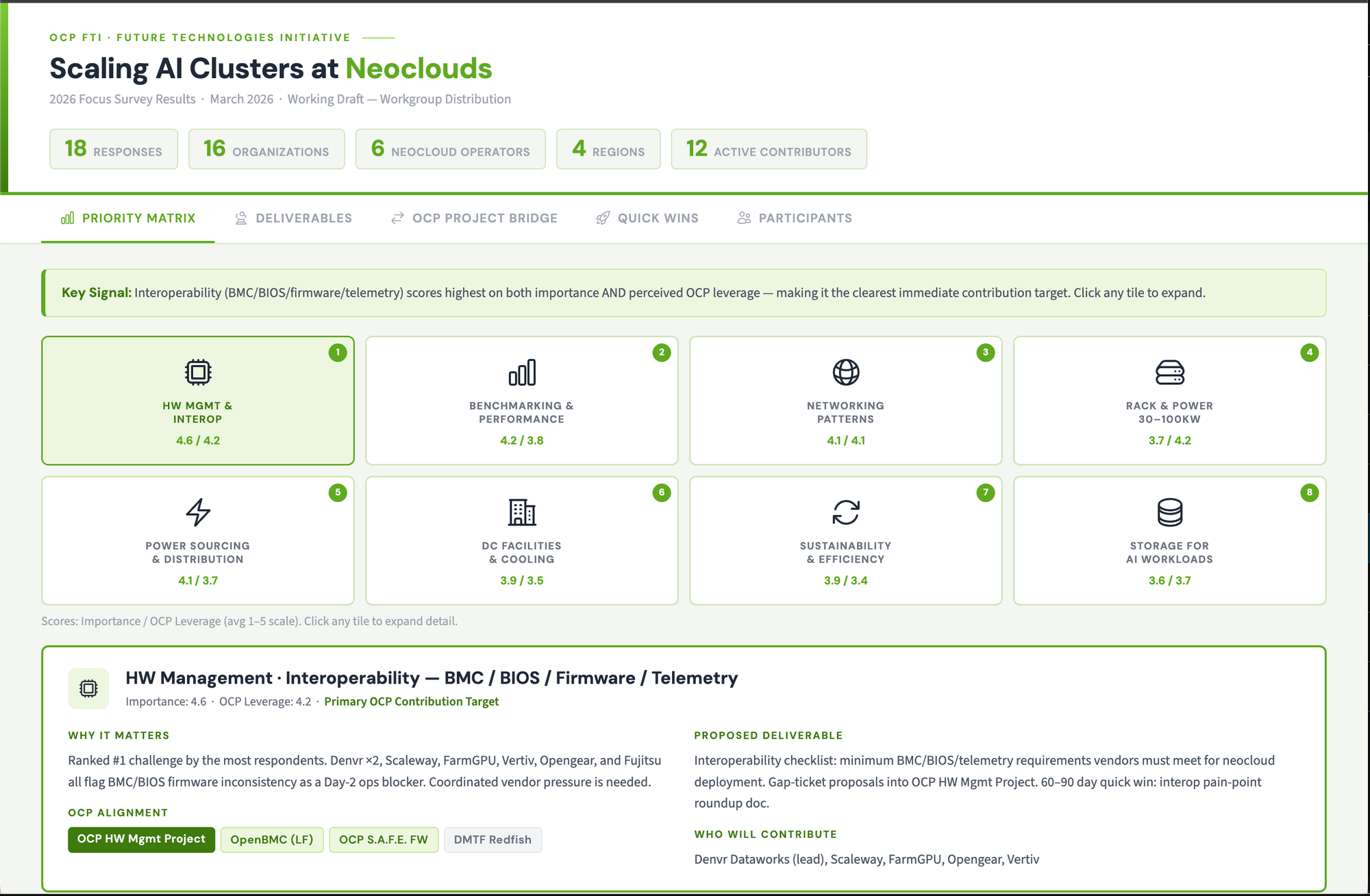
What 2026 focus areas matter most
| Focus area | Importance (avg) | OCP leverage (avg) |
|---|---|---|
| Power sourcing + distribution architectures | 4.21 | 3.68 |
| Benchmarking + performance assurance | 4.05 | 3.79 |
| Interoperability (BMC/BIOS/firmware/telemetry) | 3.95 | 3.84 |
| Sustainability + efficiency practices | 3.95 | 3.79 |
| Networking patterns + tuning guidance | 3.89 | 3.89 |
| Facilities + cooling readiness | 3.63 | 3.47 |
| Open rack/pod reference patterns (30–100kW) | 3.58 | 4.11 |
| Storage patterns for AI workloads | 3.47 | 3.42 |
Read those two columns together: power and benchmarking are the most important problems, but the area where the community thinks OCP can help most is open rack and pod reference patterns for 30–100kW racks — exactly the modular building-block work the Open Cluster Designs project is producing.
The most pressing operator challenges
- Networking architecture (RoCE/IB, topology, congestion control, NIC tuning) — 9 responses
- Management & automation (provisioning, firmware, orchestration, Day-2 ops) — 8
- Interoperability & vendor lock-in (BMC/BIOS/firmware consistency, telemetry) — 8
- Power availability / grid constraints / energy sourcing strategy — 7
- High-power rack & pod patterns (30–100kW racks; modular pods below 1MW) — 6
The signal is consistent: at neocloud scale, the operational surface area — networking tuning, multi-vendor firmware/BMC/telemetry, day-2 provisioning — eats more time than any single piece of hardware.
That data is now driving how the workstream organizes its 2026 calendar — including the deep dives.
Hardware management deep dive — April 13, 2026
The interoperability and management theme above isn't theoretical, so we ran a focused OCP Hardware Management deep dive with the community. To prepare, FarmGPU built a microsite that indexes every OCP hardware-management work area (Manageability Profiles, Redfish, OpenBMC, SPDM, Liquid Cooling Management, etc.) into a single navigable map of specs, work groups, and pain points so neocloud engineers don't have to dig through eight separate project pages to figure out where to plug in.
OCP hardware management experts — including Jeff Hilland (OCP HW Mgmt project chair), Jeff Autor (HPE / Redfish Forum), and Mike Rainier — joined to answer questions live.
What came out of the discussion:
- Redfish works, with caveats. Operators reported solid Redfish support on Dell servers but inconsistent behavior on other OEMs — gaps requiring IPMI fallbacks, telemetry inconsistencies, and event-subscription quirks. Every operator is independently re-discovering the same gaps and asking the same vendors for the same fixes, one customer at a time.
- OCP Redfish profiles can change that. A Redfish profile is essentially a machine-validatable requirements document — a spec of what BMC/firmware behaviors a server must support. Mike Rainier walked through how profiles can be validated against live systems, and Jeff Autor confirmed OEMs already accept customer profiles (Dell has accepted them before).
- A "neocloud profile" is the obvious next step. Rather than each operator filing individual tickets with each OEM, the workstream can publish a collective neocloud Redfish profile that codifies the BMC, firmware, TLS, telemetry, and event-subscription requirements neoclouds actually need. One set of requirements OEMs implement against — and a checklist operators validate procurement against.
- Specific gaps surfaced: GPU integration in Redfish, security/SPDM attestation standardization, and provisioning-stack consistency across vendors.
- Adjacent profile work is alive. Redfish profile work in liquid cooling management is more mature than in power today — both are areas where neocloud requirements can usefully shape the roadmap.
Part 3 — How FarmGPU is using OCP today
We're not just chairing the workstream — FarmGPU is putting OCP to work in production, and contributing the patterns back. Three areas worth calling out.
1) The first neocloud running an OCP backend fabric
FarmGPU is the first neocloud to deploy on the OCP Open Cluster Designs–aligned AI Training Fabric Reference Architecture, which we co-developed with Hedgehog and Celestica as a contribution to OCP. The RA is a network-centric, prescriptive complement to the OCP Open Cluster Designs OPG-M (Open Pod Group of M xPUs) and XOC-N (xPU Open Cluster of N xPUs) system architecture papers.
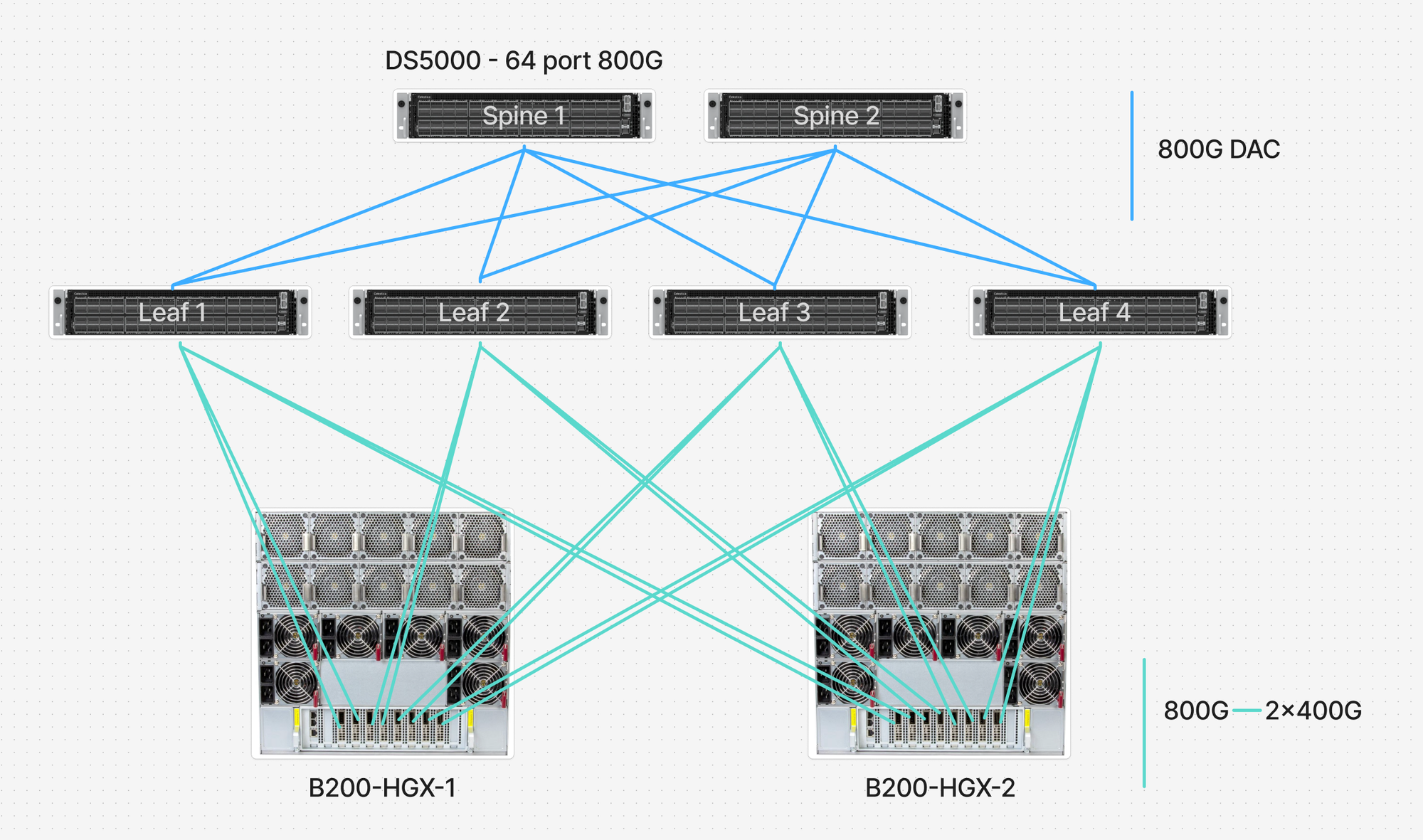
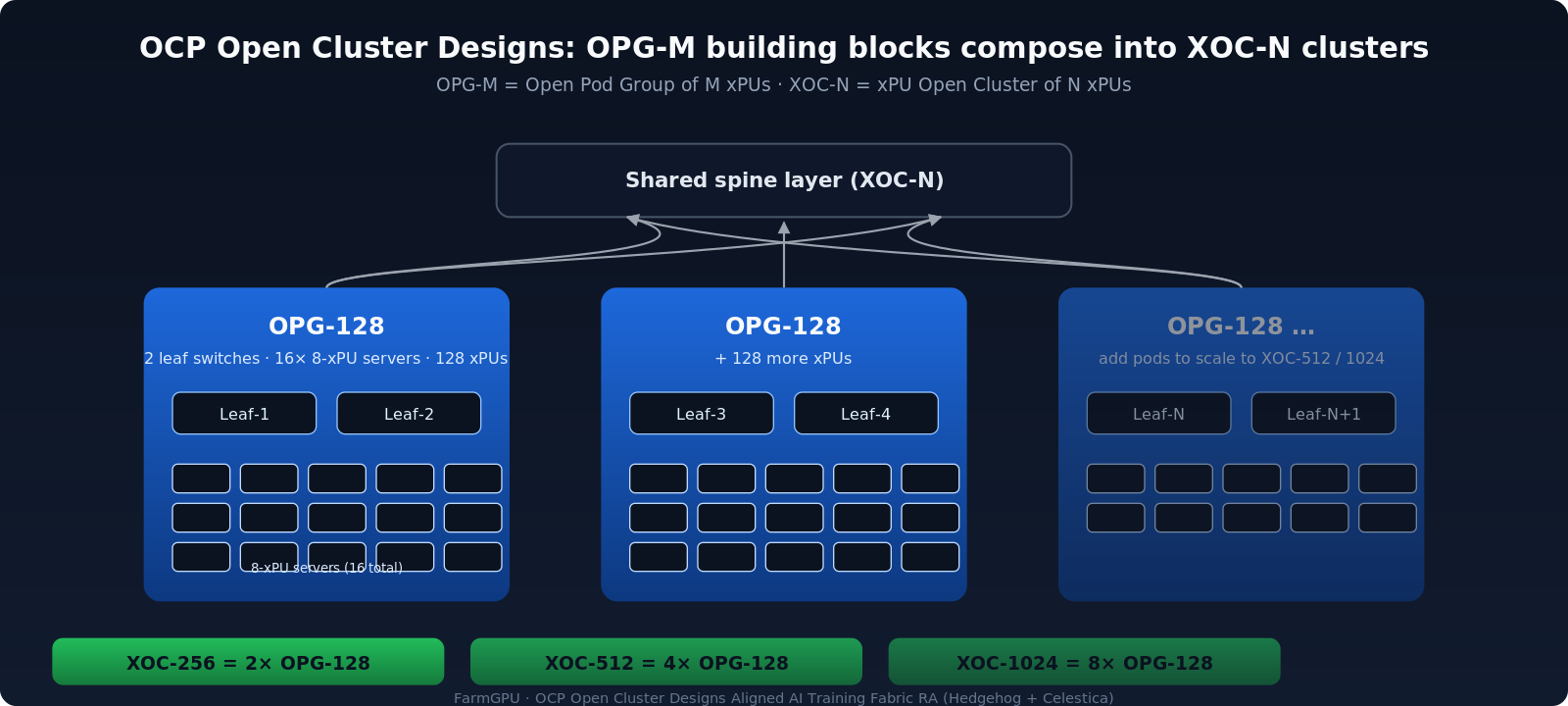
Schematic showing two OPG-128 pods plus a faded third composing into an XOC cluster under a shared spine, with XOC-256/512/1024 size labels.OPG-M building blocks compose into XOC-N clusters under a shared spine. The Training Fabric RA delivers 36 ready-to-deploy composition variants spanning OPG-64/128/256/512 and XOC-256/512/1024 in air- and liquid-cooled densities.
Key elements of the RA:
- OCP-compliant 51.2T switching as the data-plane reference (Celestica DS5000), with vendor portability via switch profiles.
- SONiC (Linux Foundation) as the open NOS on the switches.
- Hedgehog as the Kubernetes-native control plane — declarative topology and overlay management via CRDs, continuous reconciliation to SONiC, GitOps workflows, and lifecycle automation across Day-0 ZTP (via ONIE), Day-1 connectivity-maps-as-code, and Day-2 observability.
- RoCE-oriented QoS, single-homed Clos and rail-optimized wiring options, and single-plane (1×400G) and dual-plane (2×400G) variants.
- 36 composition variants spanning OPG-64/128/256/512 building blocks composing into XOC-256/512/1024 clusters, in both air-cooled and liquid-cooled densities, with connectivity maps, BoMs, and Hedgehog CRDs as ready-to-deploy artifacts.
For the inference side, the companion OCP AI Inference Fabric Reference Architecture (also Hedgehog + Celestica) targets multi-tenant inference at the 32–256 xPU scale with two profiles — Minimal Inference (no back-end RDMA fabric) and Distributed Inference (adds a dedicated RDMA back-end with one-toggle RoCE enablement) — plus a distributed open-source Hedgehog Gateway on x86 for NAT/PAT and ingress/egress.
The point of contributing both RAs is not "buy this exact stack." It's giving every neocloud — and every OCP-aligned colo and OEM partner — a vendor-neutral, declarative, reproducible starting point for AI fabric deployment that doesn't lock anyone into a single vendor's reference network design.
2) Adopting the OCP NVMe SSD specification — and building a predictive failure engine on top of it
FarmGPU standardizes on the OCP Datacenter NVMe SSD Specification for our storage layer. The OCP NVMe SSD spec is one of the cleanest examples of how operator-driven OCP work compounds: it started as Meta + Microsoft requirements, was adopted by Dell, HP, and the broader OEM ecosystem, and is now a de-facto datacenter SSD baseline — better health telemetry, sanitization behavior, latency outliers, power management, and security than vanilla NVMe. We use it as the spec we hold our SSD vendors to.
The richer telemetry surface is exactly what makes proactive drive replacement possible at neocloud scale. We've built an internal FarmGPU Predictive Failure Engine that consumes OCP-spec health/SMART logs across the fleet, scores drives for NAND degradation, ECC escalation, and recoverable/uncoverable error trends, and surfaces actionable recommendations (replace, watch, monitor) per drive — across all hosts, GPU servers and storage nodes alike.
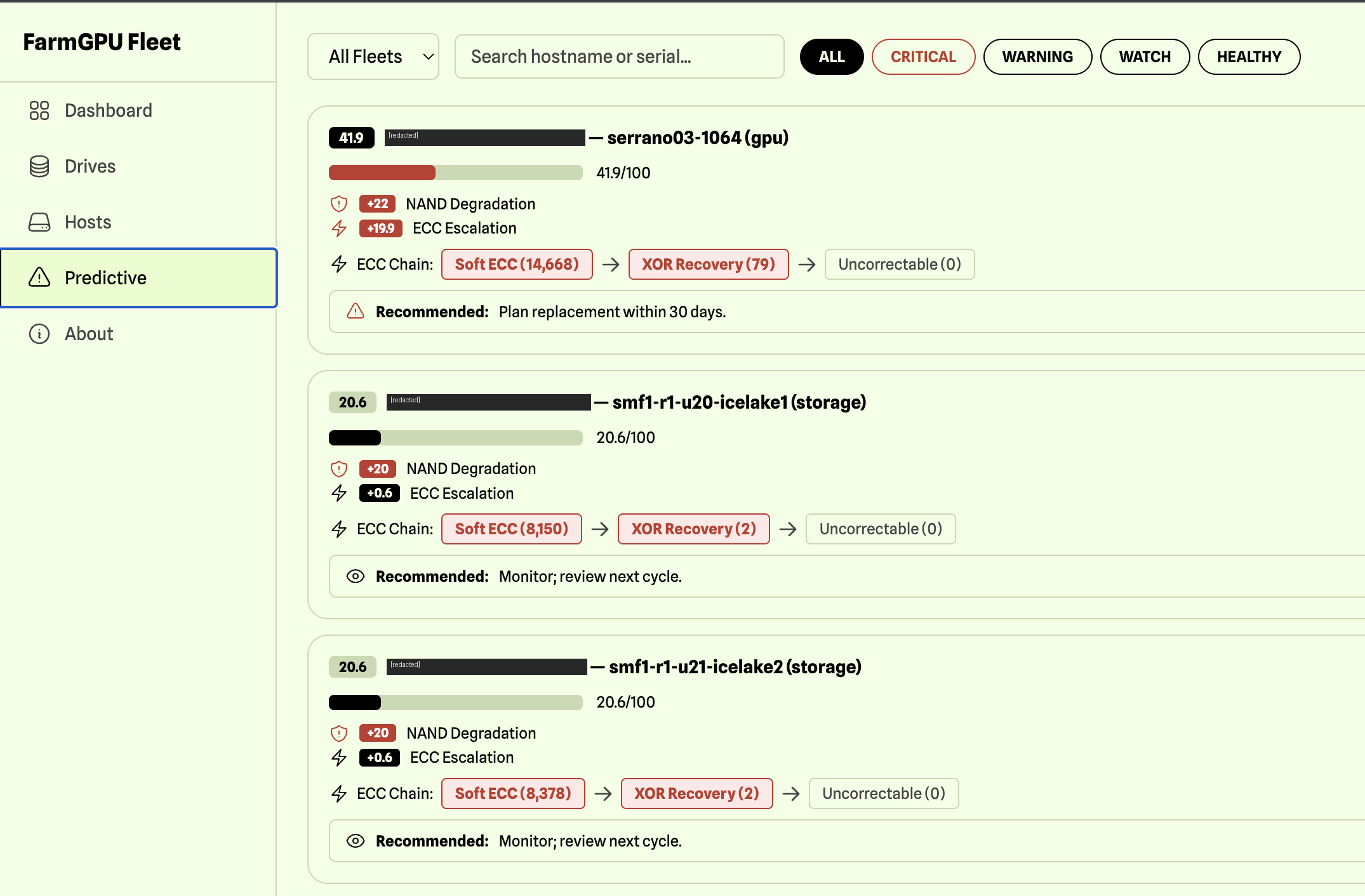
FarmGPU Fleet Predictive screen showing drive risk scores, NAND degradation, ECC escalation, and recommendations across multiple hosts
3) Helping organize the neocloud playbook in 2026
Internally, FarmGPU is committing to:
- Co-leading the workstream with Scaleway and Denvr Dataworks.
- Driving the hardware-management profile work — including a draft "neocloud Redfish profile" the community can comment on.
- Contributing benchmarking and TCO data (anonymized where needed) into the case-studies deliverable.
- Hosting the hardware-management microsite as living documentation.
Get involved
If you build, operate, sell into, or buy from neoclouds, the workstream is open. We meet monthly (with deep-dive sessions every two weeks for active topics), and the next focus areas — driven directly by the survey results above — are power architectures, facilities readiness, networking, and management/automation.
Questions or want to help? Email me at [email protected].
OCP's slogan is community-driven hyperscale innovation for all. In the AI era, "all" has to include the neoclouds — and the operators who are pickier about real, measurable performance than anyone else in the industry. That's the bar we're aiming at.