

When looking at the economics of running a production inference endpoint, the only thing that matters is $ TCO / M tokens. When per user context increases, it blocks the HMB / VRAM from being used to get more users and dramatically impacts total bandwidth / throughput of tokens / s, which is critical to lowering the TCO.
I am thrilled about what we are showing at NVIDIA GTC 2026 next week. FarmGPU, together with Lightbits Labs and ScaleFlux, has built a collaborative architecture that delivers 100x to 280x acceleration on KV cache workloads — and it fundamentally changes the economics of long-context AI inference.
- Viability in Sensitive Environments: It makes small, single-system inference—critical for confidential computing and sovereign AI stacks—economically and technically viable by eliminating GPU stalls for multi-user and turn-based chats.
- Lower TCO for LLMs: It frees up valuable High-Bandwidth Memory (HBM) on the GPU by moving the KV cache to disaggregated storage, we achieve increased batch sizes, higher effective utilization, and lower cost per token, dramatically lowering the overall TCO.
- Disruptive Context Scale: Enabling new, multi-million-token, disruptive long-context workflows for challenges like entire codebase refactors and new scientific discoveries.
The KV Cache Problem Nobody Talks About
If you have been following our work at FarmGPU, you know we have been hammering on the thesis that storage is not a passive participant in AI infrastructure — it is a performance-critical layer that determines GPU utilization and total cost of ownership. I wrote about this extensively in The Neocloud Storage Imperative, and what we are announcing today is a direct embodiment of that principle.
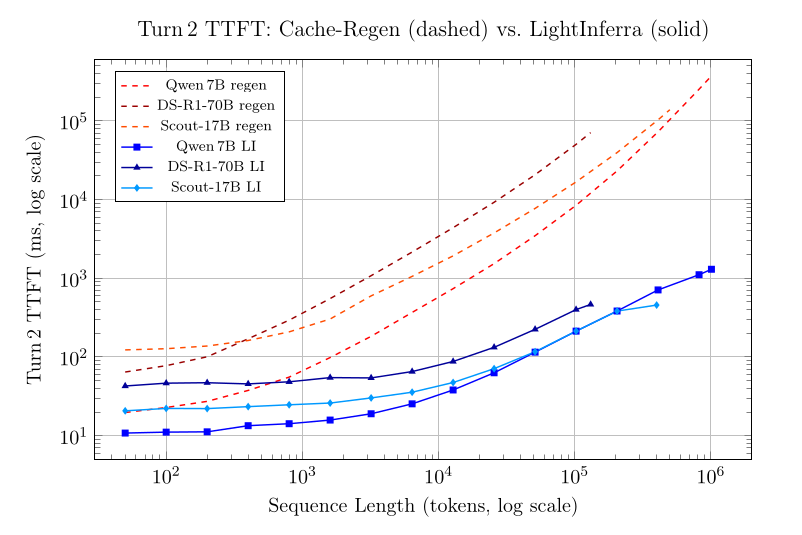
Here is the core problem: a KV (Key-Value) cache holds token attention vectors in GPU high-bandwidth memory (HBM). As models grow and context windows expand to hundreds of thousands or millions of tokens, the memory required by the KV cache has been more than doubling every year. When HBM fills up — and it fills up fast on long-context workloads — those cached states get evicted. The GPU then has to recompute them from scratch, which is computationally expensive and introduces massive latency spikes in Time-to-First-Token (TTFT) and Time-Per-Output-Token (TPOT).
The result? GPUs sitting idle waiting for data they already computed once. Inference throughput tanks. Costs per token go through the roof. And your users experience the kind of latency variance that makes production deployments unreliable.
Enter LightInferra: Treating Inference Memory as a Streamed Data Layer
The architecture we have built flips this model on its head. Instead of letting valuable KV cache states get evicted and recomputed, Lightbits’ LightInferra software persists them across a tiered memory hierarchy — from GPU HBM to system DRAM to ScaleFlux NVMe SSDs — and intelligently prefetches them back into GPU memory over high-speed RDMA before they are needed.
- GPU Layer — FarmGPU managed inference environment
- Cache Software — Lightbits LightInferra™ intelligent prefetching over RDMA
- Storage Layer — ScaleFlux PCIe 5.0 NVMe SSDs
- Transport — RDMA 800G Network
Think of it as applying decades of CPU cache architecture principles to the GPU inference pipeline. Processors have not stalled waiting for data since we figured out multi-level caching and prefetching in the 1990s. It is time inference systems caught up.
Arthur Rasmusson, Director of AI Architecture at Lightbits Labs, put it well:
“We are transforming inference memory from a reactive cache into an intelligent, streamed data layer.” That is exactly right. By prefetching only the data that matters and delivering it to GPUs over RDMA before it is needed, the system eliminates the stalls that traditionally limit long-context performance.
The Numbers: 100x–280x Speedup, 3× More Requests, 65% Cost Reduction
Let me be specific about what we are seeing in testing, because the numbers are striking:
100x to 280x speedup on KV cache read workloads using LightInferra reading cached attention states off ScaleFlux storage SSDs, compared to full recomputation.
Up to 3× more inference requests served on the same GPU hardware. By extending and sharing the KV cache beyond limited GPU memory, we eliminate the redundant computation that has been eating GPU cycles.
65% reduction in power and infrastructure costs. When you stop recomputing attention states that you already have on fast storage, the energy and hardware savings are dramatic.
Lower and more stable TTFT and TPOT. Retrieving attention states from storage instead of recomputing them means your latency is predictable, not spiky.
These are not theoretical projections. This is what Lightbits has measured in testing on our infrastructure, running real inference workloads on FarmGPU’s managed GPU clusters with ScaleFlux NVMe underneath.
| Model & Sequence Length | Baseline TTFT | LightInferra TTFT | Overall Improvement |
|---|---|---|---|
| DeepSeek-R1-70B @ 131 k tokens | 70.8 s | 465 ms | 152 |
| Qwen 2.5-7B @ 410 k tokens | 72.6 s | 711 ms | 102 |
| Qwen 2.5-7B @ 1.01 M tokens | 372.3 s | 1.3 s | 286 |
| Llama-4-Scout-17B @ 400 k tokens | 103 s | 457 ms | 226 |
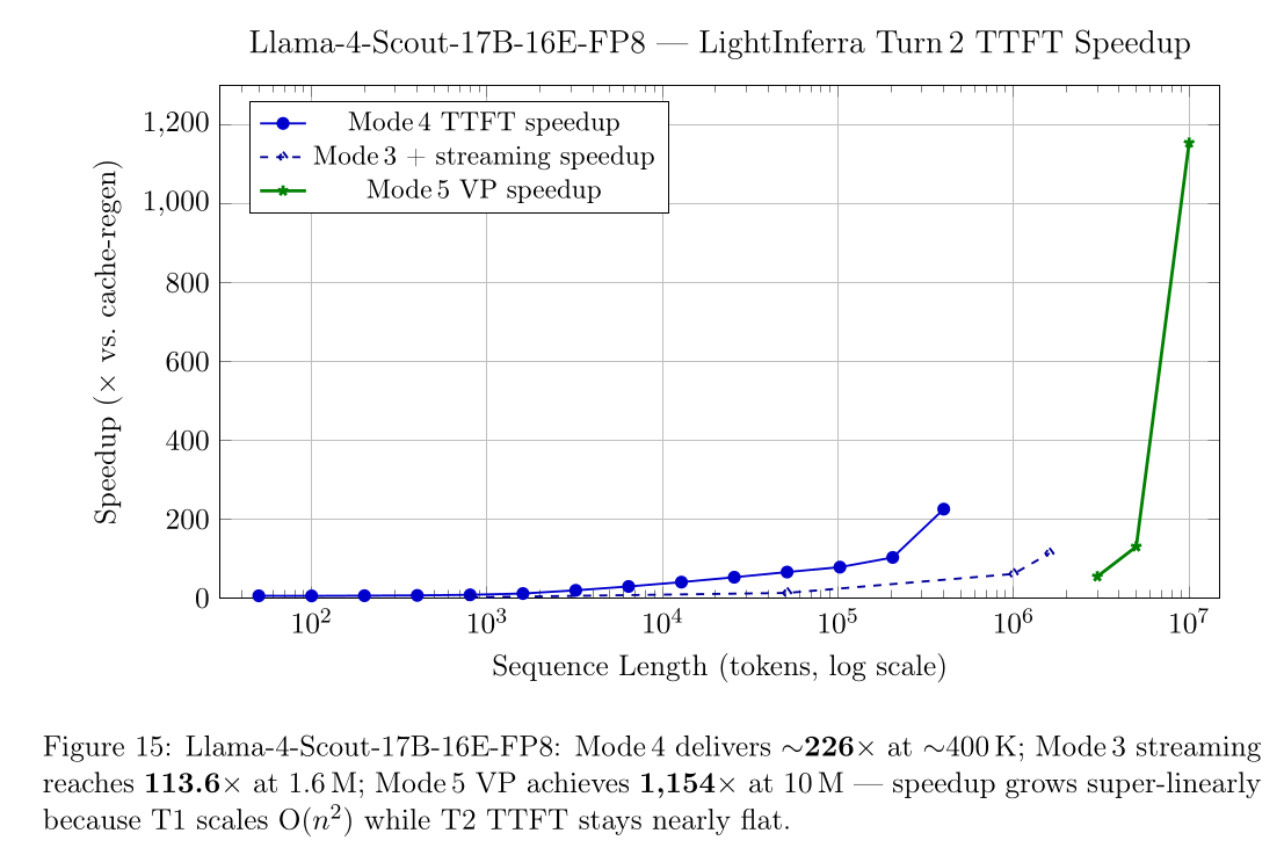
Yesterday, we ran Llama-4-Scout to 10,000,000 input tokens. See our results below. We showed a 1,154x time to first token in Llama-4-Scout, which is the maximum supported sequence length for this model.
Why ScaleFlux Storage Matters Here
ScaleFlux provided their latest PCIe 5.0 NVMe SSDs for the evaluation. The data coming off the drives is already optimized for the access patterns LightInferra needs, reducing the I/O overhead that would otherwise bottleneck the prefetching pipeline.
Keith McKay, Senior Director of Solutions Architecture at ScaleFlux, noted
As members of the NVIDIA Magnum IO GPU Direct Network, we see this as an opportunity to collaborate openly with the ecosystem.” What they are showing at GTC is an early look at how smarter data placement and persistent attention state management can help inference systems stay responsive as context windows scale.
Why FarmGPU? The Neocloud Advantage
This is exactly the kind of infrastructure innovation that neoclouds are built for. Hyperscalers optimize for generality — they need their infrastructure to support everything from web servers to databases to AI training. Neoclouds like FarmGPU optimize for a specific, high-value workload class and build the most efficient infrastructure possible around it.

While this demo was put together on an L40S, the GPU layer can be easily swapped with any GPU in our fleet depending on model size and tokenomics. We chose this last generation model for this demo to showcase that even older hardware can acheive this insane long context.
Fast networked storage from Lightbits unlocks a lot of new use cases for long-context inference. By pairing FarmGPU’s managed service with Lightbits’ high-performance storage running on ScaleFlux NVMe, we are able to lower time to first token and increase utilization on GPUs, drastically lowering the TCO for inference.
This matters because GPU utilization is the single most important economic lever in inference infrastructure. Every percentage point of utilization you recover translates directly to lower cost per token. When you can serve 3× more requests on the same hardware, you have fundamentally changed the unit economics.
What Comes Next: Design Partners and GTC
This announcement marks the beginning of a design-partner-driven effort. We are actively seeking feedback from AI infrastructure teams, platform builders, and service providers running large-scale or long-context inference workloads. If you are dealing with KV cache pressure on your GPU fleet, we want to talk to you.
ScaleFlux will be at GTC in San Jose, March 17–20, at Booth 7006. Come see the live demo of LightInferra running on ScaleFlux storage, serving KV cache data to GPUs in FarmGPU’s infrastructure. It is one thing to read about 100x–280x speedups. It is another to see it running.
The era of brute-force KV cache recomputation is ending. The future of inference is intelligent, tiered, and storage-aware — and we are building it.
Resources
Press release: ScaleFlux, FarmGPU, and Lightbits Labs Preview Solution to Solve Long-Context AI Inference at NVIDIA GTC
Related: The Neocloud Storage Imperative: Architecting the Data Foundation for the AI Factory